
Article Author
April 10, 2017
Link to Original Article
Much has been said about how big data will help solve many of the world's thorniest problems, including pandemics, hunger, cancer treatments, and conservation. However, because of the seriousness of the problems, and complexity of big data and its analysis, a great deal of testing is required before any results can be considered trustworthy. Unfortunately, most businesses and organizations do not have the in-house capability to achieve any semblance of trust. Thus, the normal procedure has been to outsource the work to third-party vendors.
The operative phrase is "has been." Big data, more often than not, contains sensitive information pertaining to individuals serviced by the organization, and releasing that information to outside resources may place the organization or business in jeopardy with state and federal privacy regulations.
A possible solution to this privacy issue
Three researchers at MIT may have figured out a way to assuage privacy concerns. Principal researcher Kalyan Veeramachaneni along with researchers Neha Patki and Roy Wedge in their paper The Synthetic Data Vault (PDF) describe a machine-learning system that automatically creates what the researchers call "synthetic data." Originally, the team's goal was to create artificial data that can be used to develop and test algorithms and analytical models. Besides generating enough data for data scientists, synthetic data can be easily massaged so as to remove the ability to associate data with a particular individual.
Synthetic data
To start, the researchers needed to decide what synthetic data would look like. They came up with the following requirements:
- To ensure realism, the data must resemble the original data statistically; and
- To allow the reuse of add-on software, the data must also resemble the original data formally and structurally.
"In order to meet these requirements, the data must be statistically modeled in its original form, so that we can sample from and recreate it," write Veeramachaneni, Wedge, and Patki. "In our case and most other cases, the form is the production database. Thus, modeling must occur before any transformations and aggregations are applied."
Veeramachaneni explains further in this MIT press release:
"Once we model an entire database, we can sample and recreate a synthetic version of the data that very much looks like the original database, statistically speaking. If the original database has some missing values and some noise in it, we also embed that noise in the synthetic version. In a way, we are using machine learning to enable machine learning."
Synthetic Data Vault
To create synthetic databases, the researchers developed a platform called the Synthetic Data Vault (SDV), which is a system of building generative models of relational databases. "We can sample from the model and create synthetic data," writes the research team. "When implementing the SDV, we also developed an algorithm that computes statistics at the intersection of related database tables."
Figure A depicts the SDV workflow: The user collects and formats the data, specifies the structure and data types, runs the modeling system, and then uses the learned model to synthesize new information.
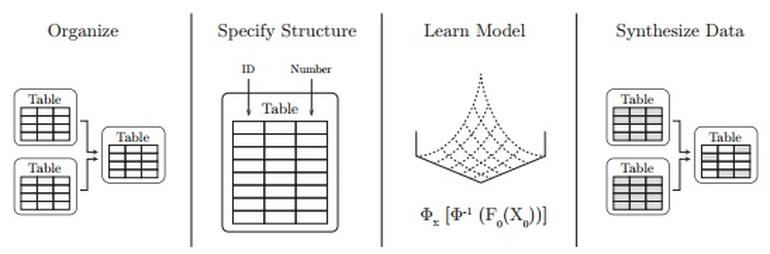
The researchers call the approach behind their SDV "recursive conditional parameter aggregation." The SDV allowed the researchers to synthesize artificial data for any relational dataset. SDV also permits the generation of as much data as required post-modeling, all in the same format and structure as the original data. And most important to this discussion, the researchers add, "To increase privacy protection, users can simply perturb the model parameters and create many different noisy versions of the data."
Testing the SDV
To test whether synthetic data, including the noisy versions, can be used to create data science solutions, Veeramachaneni, Wedge, and Patki modeled five different relational datasets creating three versions of synthetic data—with and without noise—for each of the datasets. They then hired 39 freelance data scientists to solve predictive problems using the five datasets.
"For each dataset, we compared the predictive accuracy of features generated from the original data to the accuracy of those generated by users who were given the synthetic data," writes the research team. "We found no significant statistical difference in the data scientists' work. For 11 out of 15 comparisons, data scientists using synthetic data performed the same or better than those using the original data."
What all this means
The beauty of the machine-learning model from Veeramachaneni and his team is that it can be configured to create synthetic data sets of any size, and this can be done quickly to accommodate development or to stress-test schedules. Artificial data is also a valuable tool for educating students, as there is no need to worry about data sensitivity.
The MIT press release concludes with, "This innovation can allow the next generation of data scientists to enjoy all the benefits of big data, without any of the liabilities."